





genCollectionInterface (gCI)

Introduction
genCollectionInterface (gCI) is a set of templates and HTML generation tools written in Python which produce a static website for a book collection. You can install the generated pages on a web server, serve then using Dropbox, or put everything on a thumb drive and browse them using the Browse Activity. The website serves the same purpose as what you could generate from calibre+OPDS, but it is more visually appealing.
These tools were created during the summer and fall of 2009 as part of the Rural Design Collective's Summer Mentoring Program. The goal of the project was to enable and/or enhance access to the Children's Book Collection of the Internet Archive on the OLPC/XO laptop platform, especially where internet access was not available. The developers considered the state of Sugar and the XO hardware and tried to create a usable and fun site that would appeal to children aged 5-15.
The tool is intended to create a subset of the Internet Archive collection that can be used when an internet connection is not available (although you will of course need an internet connection to get the books to begin with). It is not something you can use for your own collection of books. For that calibre is the best option.
If you want to make the Children's Book Collection available to your students you'll need a thumb drive that can hold six gigabytes of data (or a local web server with that much disk space available). Before you start, go to
http://ruraldesigncollective.org/lab/ui/
and check out the collection of books to see if it is something you want. The books are in the public domain, so they are quite old and some will not find favor with a modern child. The website at this URL is similar to, but not exactly the same as, the one you would be setting up, so make sure you want it before continuing.
The Website
The website is accessible to children who have just started reading while also providing features for experienced readers. Books are organized into categories as shown below:
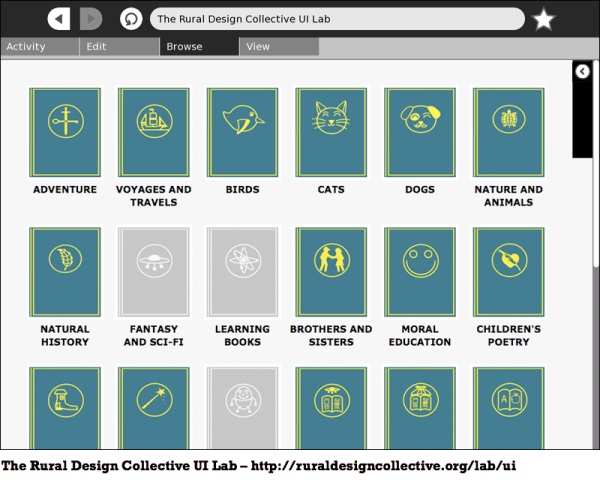
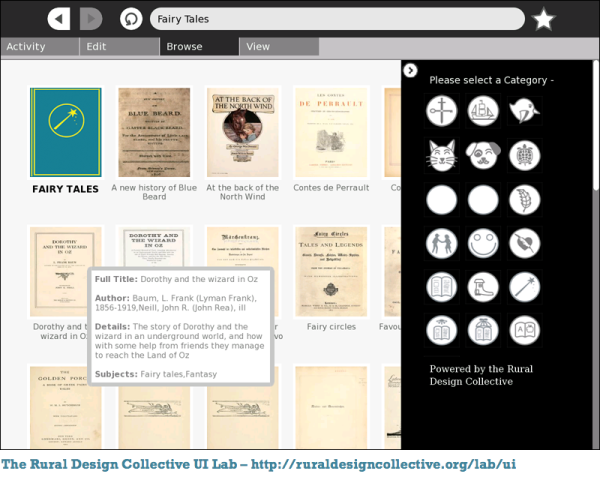
The titles are displayed below the icons, and the author, date, description of the book are displayed in a "tool tip" when the mouse pointer is over the icon. When you click the icon the book is shown in an online book reader page (see below). That is a key difference between what is on the RDC website and what you will be creating locally. In your local version clicking on a book will download it and copy it to the Journal.
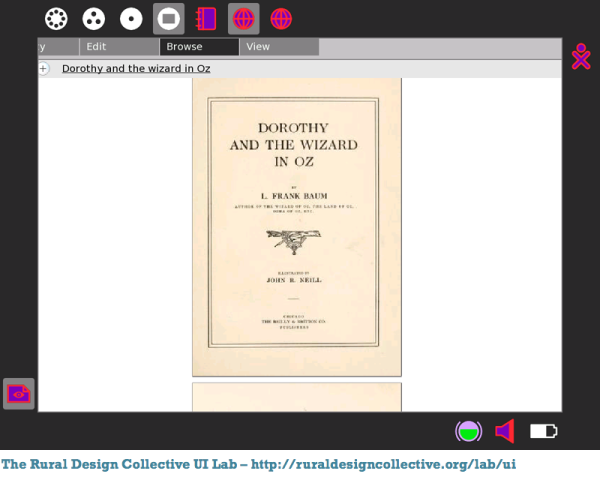
The books are in the DjVu format, which is supported by any version of Sugar later than .82.
Installation
Install the tools by downloading and unzipping the distribution archive. Do this in a dedicated directory to avoid overwriting files. You can download the distribution archive here:
https://github.com/scottyrdc/GenCollectionInterface
On the right side of this page is a Downloads button. Choose the Download .zip option that appears after you click on the Downloads button. Unzip the archive.
The archive contains everything you need with the exception of the books themselves. To get those you will need to run a Python script, and before you can do that you'll need a program called wget.
wget is installed or available for any Linux distribution. If you're using Linux then it is probably installed already. You can also download a version of wget for Windows here:
http://gnuwin32.sourceforge.net/packages/wget.htm
The script is named dl.py and it will be found in the directory you just unzipped. It will create directories named djvu and covers and download the e-books and their cover images into these directories. There is over five gigabytes to download so it should take a few hours on even a fast connection. To run the script just do this:
python dl.py
When this is finished running look for a file named index.hand-edited-example.html.txt and copy it to the name index.html. Try loading this file into a web browser. It should bring up your website ready to go, with all the book links pointing to your local directory. If it doesn't you'll need to generate some pages yourself, but don't do these next steps unless you're sure you have to.
There is another script called genCollectionInterface.py which generates HTML pages and JavaScript. Before you can run it you'll need to delete all the files ending in .html and .js from the directory you unzipped to (but NOT the subdirectories). Once you've deleted the files you can run the command like this (all on one line):
python genCollectionInterface.py -attached-storage search.CSV categories.txt
You will see numerous messages as the files are parsed and output is generated, and when the process is completed there will be a directory full of HTML and JavaScript files. The ones used for the interface are called <Category>Category.html, for example Adventure and AdventurersCategory.html, or for JavaScript files, <Category>ToolTip.js, for example Adventure and AdventurersToolTip.js There's also a catch all category: Other, where anything not in categories.txt will go.
Recreate your index.html file if you deleted it, and your site should be ready to copy to a web server or thumb drive. An important note about the thumb drive: Sugar will mount the drive at a location called /media/VolumeName where VolumeName is the label of the drive. It is important that you give your thumb drive a short and meaningful volume name, like books. You may need to format your drive to give it this name, so do that before you copy the data into it. If you do everything right, you'll be able to use the website from the Sugar Browse Activity using the following URL:
file:///media/books/index.html
About The Collection
The Internet Archive Children's Library is a digital repository of over 3,300 digital public domain books for children from around the world. The Rural Design Collective selected a subset of these books and created a child-friendly user interface for the OLPC XO as part of their 2009 Summer Mentoring Program.
If you want to try creating a collection from the Internet Archive other than the Children's Library you can read more about genCollectionInterface at: