Sugar Activities For Finding E-Books

Introduction
The Sugar environment uses a Journal to keep all the student's work in, instead of using files and directories. Every e-book you read will have its own entry in the Journal. In addition to the file for the book the entry will have metadata about the book, including a meaningful Title, a Description of the book, and Keywords.
If you download all your books using the Browse Activity you'll find that the file you download will often have a meaningless name and the Title it will have in the Journal will be long but still meaningless. You would need to correct the Title and perhaps add a Description for the book yourself.
There is a better alternative to using Browse for most of your e-book downloading needs. In fact, there are three of them.
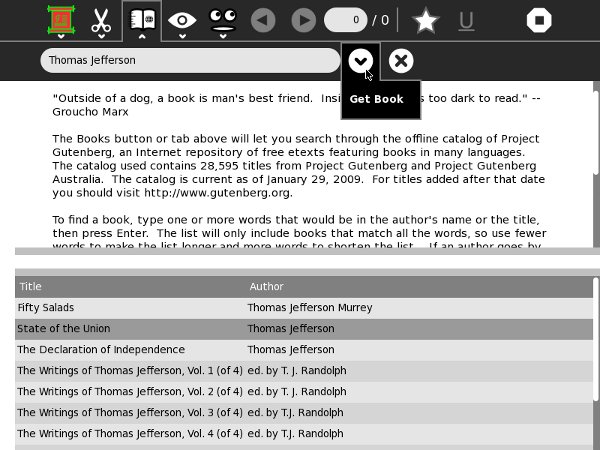
Get Books
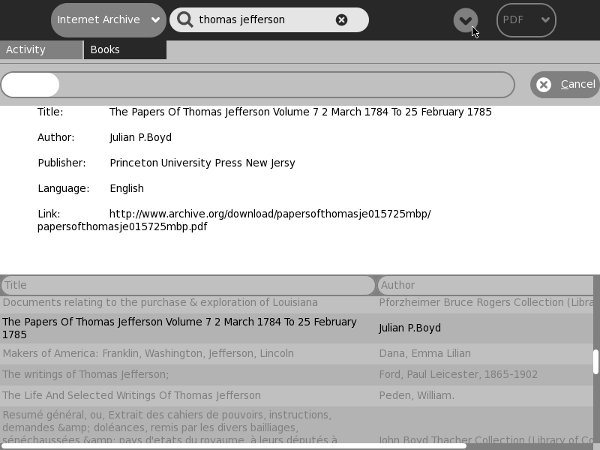
The Get Books Activity is the newest of the three. It lets users search for books from multiple online sources such as the Internet Archive and Feedbooks. It also provides support for removable devices ("Library on a Stick") which have OPDS catalogs in the root directory. OPDS (Open Publication Distribution System) is a kind of book catalog that anyone who publishes e-books can create. Currently the Internet Archive and Feedbooks have such catalogs, so Get Books can download titles from their catalogs. Feedbooks has titles from Project Gutenberg converted to PDFs. This means that you can find and download the majority of free e-books available to your Journal using this Activity.
This is what the Activity looks like downloading a book about Thomas Jefferson:
OPDS is part of the BookServer ecosystem which has been described as follows:
"The BookServer is a growing open architecture for vending and lending digital books over the Internet. Built on open catalog and open book formats, the BookServer model allows a wide network of publishers, booksellers, libraries, and even authors to make their catalogs of books available directly to readers through their laptops, phones, netbooks, or dedicated reading devices. BookServer facilitates pay transactions, borrowing books from libraries, and downloading free, publicly accessible books."
It is possible to customize Get Books by adding more OPDS feeds to it. One such feed can come from a Pathagar Book server, which I'll describe later in its own chapter. Unfortunately, you'll need some experience with the Unix command line to do this. Use the Terminal Activity and become the root user. In the directory where your Activity is installed, generally named ~/Activities/GetBooks.activity, you'll find a file named get-books.cfg. As root, make a copy of this file in the /etc directory. Anything you put in this file will override what was in the original get-books.cfg file.
Some Sugar deployments don't give their users root access to the computer. If you are in that situation you can make a copy of get-books.cfg in the ~/Activities/GetBooks.activity directory and modify the original. You can revert back to the copy if things go wrong.
The file is organized into sections that look like what Windows .INI files used to have. Add a new section for each OPDS feed you have. You'll need to use the vi editor. Here is a new section for a local Pathagar Book Server:
[Pathagar Book Server] name = Pathagar Book Server query_uri = http://pathagar.myschool.edu/feed.atom?q= opds_cover = http://opds-spec.org/image
To use Get Books with a removable device like a thumb drive you need to create an OPDS catalog with the name catalog.xml and put it in the root directory of the drive. Get Books will look for that file and if it finds it then the drive will be listed as one of the possible ODPS sources in the drop-down list.
Here is Get Books using its new OPDS catalog:
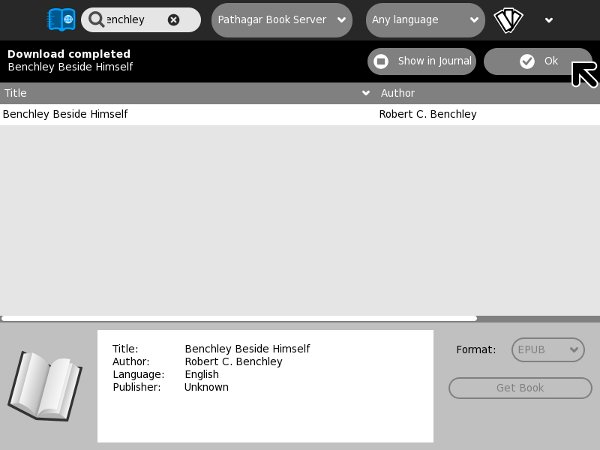
While calibre can create a collection with an OPDS catalog, at this time the catalog it produces is a little fancier than what Get Books is able to use. calibre's catalog is a hirearchy of XML files that allows you to drill down from a list of books down to individual book details. What Get Books needs is a file where the list of books and the book details are all in one file, like this:
<?xml version="1.0" encoding="UTF-8"?>
<feed xmlns:opds="http://opds-spec.org/"
xmlns:dcterms="http://purl.org/dc/terms/"
xmlns="http://www.w3.org/2005/Atom"
xmlns:opensearch="http://a9.com/-/spec/opensearch/1.1/"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<id>pathagar:full-catalog</id>
<title>Pathagar Bookserver OPDS feed</title>
<subtitle>OPDS catalog for the Pathagar book server</subtitle>
<updated>2011-06-13T12:03:26Z</updated>
<entry>
<id>0e00c034-95df-11e0-ba86-00096b32bd5b</id>
<title>Benchley Beside Himself</title>
<updated>2011-06-13T12:03:26Z</updated>
<author>
<name>Robert C. Benchley</name>
</author>
<link href="/book/4/download"
type="application/epub+zip"
rel="http://opds-spec.org/acquisition"></link>
<link href="/covers/cover_1.jpg"
rel="http://opds-spec.org/cover"></link>
<content>Bob Benchley delivers the laughs.
</content>
<dcterms:language>en</dcterms:language>
</entry>
<entry>
<id>cae190c6-95de-11e0-ba86-00096b32bd5b</id>
<title>The Big Sleep</title>
<updated>2011-06-13T12:01:53Z</updated>
<author>
<name>Raymond Chandler</name>
</author>
<link href="/book/3/download"
type="application/epub+zip"
rel="http://opds-spec.org/acquisition"></link>
<link href="/covers/cover.jpg"
rel="http://opds-spec.org/cover"></link>
<content>Private Eye Philip Marlowe gets
involved with dizzy dames with something
to hide.</content>
<dcterms:language>en</dcterms:language>
</entry>
</feed>
Get Internet Archive Books
Get Internet Archive Books is very similar to Get Books, and in fact Get Books began life as a modified copy of Get Internet Archive Books, and they continue to use the same icon. Before the Internet Archive got behind OPDS they had (and continue to have) something called Advanced Search. OPDS takes a query and returns XML. Advanced Search can return several formats, but the one Get Internet Archive Books uses is comma delimited lines. Because of this it will never work with anything other than the Internet Archive. On the other hand, because it restricts itself to just one source of books it can do things that Get Books can't do. For instance, it can download e-books in all four formats that IA offers: PDF, B/W PDF, Deja Vu, and EPUB. Second, in the search results listing you will see Title, Volume, Author, and Language where Get Books only shows title and author.

Read Etexts
Read Etexts is an Activity meant to read the Plain Text files produced by Project Gutenberg and Project Gutenberg Australia. These sites do not yet support OPDS but they do both provide text files that can be used as a catalog of what books are available and how the files are named and stored on their systems. PG began in the days when MS-DOS was the most popular operating system for personal computers, so all of their files have eight character file names. In the first few years they were in operation they tried to make these short names somewhat meaningful, but they later changed to a new system which gave every book a completely meaningless number. Some of the old books have been renamed to the new format, others have not. Also, while just about every book has a 7-bit ascii format file available many have and need another encoding that can represent the accents, umlauts, and ligatures used by languages other than English.
When you download a book using Read Etexts it tries to make sense of all this for you. It looks for an 8-bit encoded file first, and if it doesn't find one it downloads the 7-bit version. It gives the Journal entry it creates a meaningful title, like Pride and Prejudice by Jane Austen rather than 56436.zip.
Another difference between the Read Etexts book search and the other two is that the book catalog is included in the Activity, so you can search for books when you are not connected to the network. The PG offline catalog is not updated often enough to justify downloading it and converting it every time you search for a book.
Read Etexts looks like this in action: